


gemini-3.1-flash-lite-preview-thinking-high:轻量极速+深度推理,性价比拉满的“轻量旗舰”
gemini-3.1-flash-lite-preview-thinking-high 是 Google DeepMind 于 2026 年 3 月 3 日推出的 Gemini 3.1 Flash-Lite 预览版 开启 High 思考模式 的专属配置,是 Gemini 3 系列中速度最快、成本最低、同时支持深度推理的轻量级多模态模型。它打破了“轻量=低能”的行业认知,在保留 Flash-Lite 极速、超低成本优势的基础上,通过 High 思考模式解锁深度推理能力,完美适配高频+复杂的生产级场景,堪称“轻量模型里的推理王者”。
一、核心定位:轻量极速+深度推理,填补行业空白
基础身份:Gemini 3.1 Flash-Lite 预览版的深度推理专属模式,是 Gemini 3 系列中最具性价比的轻量旗舰。
核心定位:专为高频、低延迟、需深度推理的任务设计,在速度、成本、推理深度三者间实现极致平衡,是海量智能体、复杂数据处理、多步骤任务的理想引擎。
核心价值:用轻量模型的成本与速度,实现接近旗舰模型的推理深度,让深度推理从“高成本奢侈品”变成“普惠生产工具”。
二、核心技术与能力:极速+深度+全能,三大优势拉满
1. 极速架构:Flash 级速度,行业天花板
基于 Gemini 3.1 Flash 极速架构,输出速度达 363 tokens/秒,较前代 2.5 Flash 提升 45%,是同价位模型中速度最快的存在。
支持 Batch API、缓存 等批量处理能力,可稳定支撑百万级/日的高并发请求,完美适配高频场景。
首 Token 响应极快,即便开启 High 思考模式,也仅比 Minimal 模式延迟增加 1–3 秒,远低于旗舰模型的深度推理延迟。
2. High 思考模式:深度推理,轻量模型的“大脑升级”
这是该配置最核心的能力,也是区别于普通 Flash-Lite 的关键:
思考机制:开启 High 模式后,模型会在生成答案前进行深度链式思考(Chain-of-Thought),通过多路径验证、逻辑推演,大幅提升复杂任务的准确性与可靠性。
模式对比:
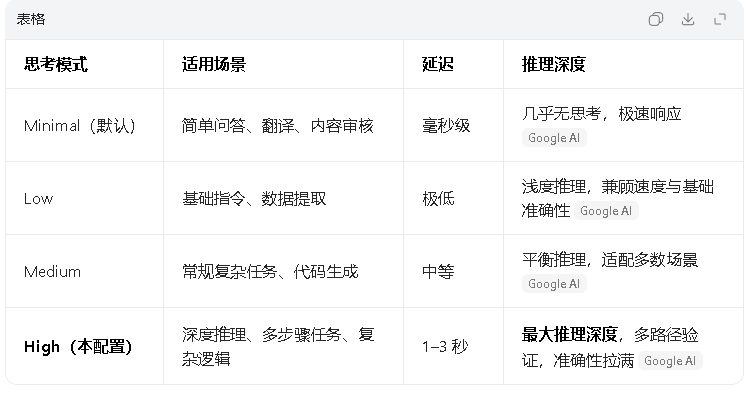
核心突破:轻量模型首次支持深度动态思考,无需切换到 Pro 级模型,即可处理复杂推理任务,成本仅为 Pro 版的 1/8。
3. 全能多模态+超长上下文:轻量不“轻能”
全模态输入:原生支持文本、图像、音频、视频、PDF,可处理图文混合、音视频理解、文档解析等复杂多模态任务。
超长上下文:输入 Token 上限 1,048,576(约 100 万),输出上限 65,536,可一次性处理整本技术文档、大型代码库、数小时会议录音,全程不丢失上下文。
工程化能力:支持结构化输出(JSON/XML)、函数调用、代码执行、文件搜索、搜索接地,可直接作为智能体完成多步骤复杂任务,完美适配企业级生产系统。
4. 极致成本:价格腰斩,普惠深度推理
定价(每百万 Token):输入 $0.25,输出 $1.50,仅为 Gemini 3.1 Pro 的 1/8,比 GPT-5 mini、Claude 4.5 Haiku 便宜 50% 以上。
性价比实测:完成相同复杂推理任务,单位智能成本仅为旗舰模型的 1/10,大规模部署无成本压力。
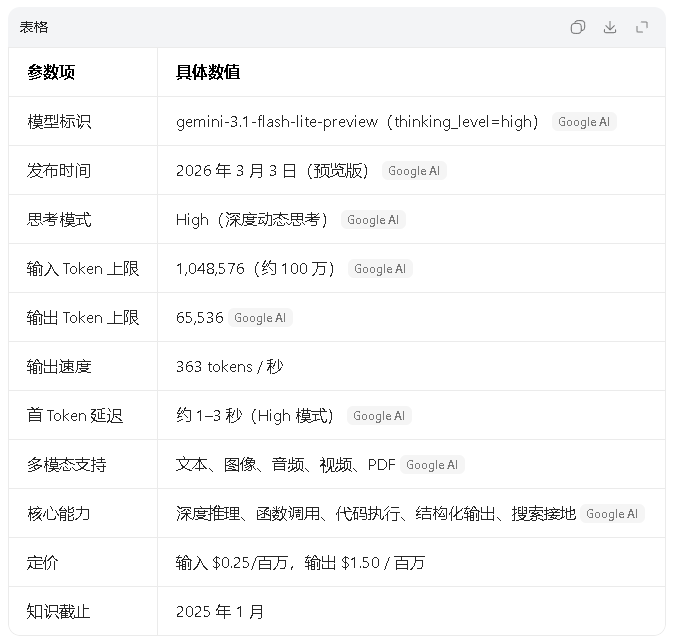
三、核心参数一览(High 模式)
四、最佳应用场景:高频+复杂,全场景覆盖
1. 海量智能体与子代理任务
大规模 AI 智能体集群的核心推理引擎,处理多步骤任务规划、工具调用、逻辑判断,高频并发下依然保持高准确性。
企业级客服、营销、运营智能体,深度理解用户意图,生成精准回复,无需人工干预。
2. 复杂数据处理与分析
长文档/多文档深度摘要、信息提取、合规审核,一次性处理百万级 Token 内容,精准提取关键信息与风险点。
科研/金融数据深度分析、趋势预测、异常检测,通过深度推理挖掘数据背后的逻辑与规律。
3. 软件工程与开发
复杂代码生成、审查、重构、调试,深度理解代码逻辑,生成高质量、可直接运行的代码,修复复杂 bug。
技术文档生成、API 接口设计、系统架构设计,适配大型项目的复杂开发需求。
4. 企业级生产级应用
金融/法律文书深度处理、合同审核、风险评估,精准提取条款、识别风险、生成合规报告。
教育个性化辅导、深度解题、知识拓展,分步拆解复杂问题,提供深度推理过程。
内容创作深度文案、创意策划、多版本迭代,高频生成高质量内容,适配内容营销需求。
五、与同系列/竞品对比:轻量旗舰,降维打击
1. 与 Gemini 3.1 Flash-Lite(Minimal 模式)对比
相同点:极速、超低成本、全模态、超长上下文。
差异点:High 模式推理深度提升 10 倍+,延迟仅增加 1–3 秒,成本不变,适合复杂任务;Minimal 模式适合极简极速场景。
2. 与 Gemini 3.1 Pro(Medium 模式)对比
优势:速度提升 2 倍+,成本仅为 1/8,延迟更低,适合高频场景。
劣势:极限推理深度略低于 Pro 版 High 模式,但90% 复杂任务表现接近,性价比碾压。
3. 与 GPT-5 mini、Claude 4.5 Haiku 对比
速度:363 tokens/秒,领先竞品 30%+。
成本:输入 $0.25/百万,仅为竞品的 1/2–1/4。
推理深度:High 模式下,复杂任务准确性超越同价位所有竞品,接近旗舰水平。
六、一键接入,数字先锋 API 解锁全能力
gemini-3.1-flash-lite-preview-thinking-high 作为谷歌最新的轻量深度推理模型,国内开发者可通过数字先锋 API 一键接入。
数字先锋 API 是一站式大模型云服务平台,已聚合 OpenAI、Claude、Gemini、DeepSeek、Grok、Qwen 等全球主流模型,支持统一调用接口,无需重复适配不同厂商,一行代码即可切换模型,同时提供高稳定、低延迟的调用服务与全链路监控,让你快速落地高频复杂场景的 AI 应用。
总结
gemini-3.1-flash-lite-preview-thinking-high 是 AI 行业的里程碑式轻量模型,它首次实现了“极速+超低成本+深度推理”的三重突破,让深度推理从“高成本专属”变成“普惠生产工具”。无论是海量智能体部署、复杂数据处理,还是企业级生产应用,它都能以极致的性价比提供接近旗舰的推理能力,是 2026 年轻量 AI 模型的首选。
免费体验最新的AI大模型,支持对话、写作、编程、图像、视频等多种功能
免费体验最新的AI大模型,支持对话、写作、编程、图像、视频等多种功能
Google模型推荐
gemini-3.1-flash-lite-preview-
gemini-3.1-flash-lite-preview-thinking-high是GoogleDeepMind于2026年3月3日推出的Gemini
gemini-3.1-pro-preview-thinkin
Gemini3.1Pro-Preview(thinkinglevel:Medium)是GoogleDeepMind于2026年2月推出的旗舰级多
gemini-3.1-flash-lite-preview-
Gemini3.1Flash-LitePreview(thinkinglevel:Medium)是谷歌于2026年3月推出的Gemini3系列中速
veo3.1-components-4k
Veo3.1-Components-4K是谷歌DeepMind推出的面向企业级工业化视频生产的高阶模块化模型,专
veo3.1-components
Veo3.1-Components是Google推出的模块化视频生成专用模型,专为需要高精度控制与多组件协同的
veo3-pro
Veo3Pro是谷歌DeepMind在2025年I/O大会上推出的旗舰级AI视频生成模型,作为全球首款实现“
gemini-2.5-pro-nothinking
Gemini2.5Pro-NoThinking是Gemini2.5Pro系列中专为“极速响应”场景设计的轻量推理模式版本
gemini-2.5-flash-thinking
Gemini2.5Flash-Thinking是谷歌Gemini2.5系列中首个支持“可控深度思考”的混合推理模型,