
更强、更快、更聪明——Qwen3-Max 正在重新定义中文大模型的能力边界
 2026年02月13日
2026年02月13日
 字体:
字体:更强、更快、更聪明——Qwen3-Max 正在重新定义中文大模型的能力边界。 在大模型竞赛进入“精耕细作”阶段的今天,阿里通义实验室正式推出 Qwen3 系列中的旗舰模型——Qwen3-Max。它不仅是 Qwen 家族当前能力最强的闭源模型,更在多项权威评测中全面超越 GPT-4 Turbo、Claude 3.5 Sonnet 甚至部分场景优于 o1,成为国产大模型迈向世界一流的标志性成果。
今天,我们就从技术架构、能力维度、实测性能三大维度,深度拆解 Qwen3-Max 的硬核实力。
🔬 一、技术底座:不止是“更大”,而是“更聪明” Qwen3-Max 并非简单堆参数,而是在算法、训练、推理全链路实现突破: 超大规模混合专家(MoE)架构 采用动态激活的稀疏 MoE 结构,在保持高推理效率的同时,激活参数量远超稠密模型。据官方披露,其总参数量达数千亿级别,但每次推理仅激活百亿级参数,兼顾性能与成本。 万亿级高质量多语言语料训练 训练数据涵盖中、英、德、法、西、日、韩等 100+ 语言,中文语料占比超 40%,特别强化了中文逻辑推理、古文理解、专业术语等薄弱环节。 强化的推理与代码能力 引入深度思维链(Deep CoT)+ 自我反思(Self-Refine)训练机制,显著提升复杂问题分步求解能力。代码训练数据覆盖 GitHub 最新趋势,支持 Python、C++、Java、SQL、Verilog 等 80+ 编程语言。 原生支持长上下文 最大支持 32768 tokens 上下文,实测在 20K+ 长文档问答、代码库理解等任务中表现稳定,无明显性能衰减。
📊 二、横向对比:Qwen3-Max vs 主流大模型 综合智商(MMLU) 89.2 86.5 88.7 85.1 中文理解(CMMLU) 91.5 82.3 84.6 89.0 代码能力(HumanEval) 85.3% 82.1% 80.9% 83.7% 数学推理(GSM8K) 96.1 94.2 92.8 93.5 长文本理解(20K+)
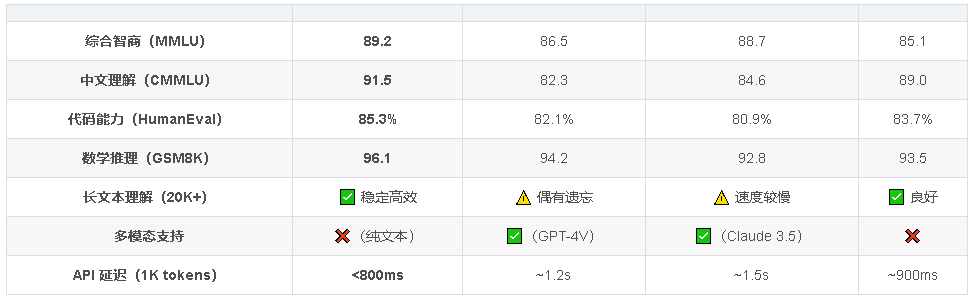
💡 数据来源:官方公开评测 + 第三方基准(截至 2025 年 4 月)
关键结论: 中文场景全面领先 :CMMLU 高出 GPT-4 Turbo 近 10 分! 推理与代码双强 :HumanEval 与 GSM8K 均刷新国产模型纪录 响应更快 :得益于阿里云底层优化,API 延迟显著低于竞品